 |
|
About | Introduction | Applications | Technical Architecture Overview | The T4U DPM Database | Other Resources | Useful links | Support/Contact
About
THIS WEBSITE IS NO LONGER MANTAINED AND MAY CONTAIN OBSOLETE INFORMATION.PLEASE CHECK THE EIOPA’S OFFICIAL T4U WEBPAGE HERE
This website’s objective is to present and explain EIOPA’s Tool for Undertakings (T4U) project.
Introduction
Solvency II creates the need for all concerned undertakings and supervisors in Europe to adapt their reporting processes. XBRL is the mandatory technical format to be used for reporting from National Competent Authorities (NCAs) to EIOPA (so-called ‘second level reporting’). A number of countries will also request submissions in XBRL from undertakings to the relevant NCA (‘first level reporting’).
The eXtensible Business Reporting Toolkit is a basic set of tools and services developed by EIOPA to help manage the process of data description, exchange, data collection, validation, storage and analysis related to the Solvency II information requirements which are modelled according to the Data Point Model (DPM) and exchanged in the XBRL format.
T4U – Tool for Undertakings
 To start the application just press here or over the left T4U icon
To start the application just press here or over the left T4U icon
The main goal of the project is to create a simple and basic tool oriented toward small and medium sized insurance undertakings to create, edit, correct, complete and validate XBRL instance documents and help firms without XBRL knowledge to implement Solvency II harmonized quantitative reporting in XBRL. The tool aims to assist undertakings that might suffer from a lack of resources to create XBRL in time for the first submission. Importantly, EIOPA expects that the tool will be decommissioned over time as companies and the Solvency II XBRL reporting chain mature.
The functionalities of the T4U are:
- Creation of input forms from the Solvency II Taxonomy;
- Conversion of the completed input forms into valid XBRL reports;
- Populating forms by opening XBRL documents;
- Giving feedback to the user when validation fails or generates warnings.
T4S – Tool for Supervisors

As a secondary goal the project aims to provide a reusable solution for other projects, in particular for local NCA requirements and EIOPA’s and the NCAs’ needs to manage XBRL reporting (T4S - Tool for Supervisors).
Scope:
- handling of XBRL reports received by the NCAs from the undertakings and facilitating second-level reporting to EIOPA;
- provision of support documentation on the creation of new input templates and/or the algorithm to generate input templates for NCA extensions;
- provision of tools that may help NCAs when creating extension taxonomies according to the Eurofiling architecture;
- establishment of basic business intelligence functionalities.
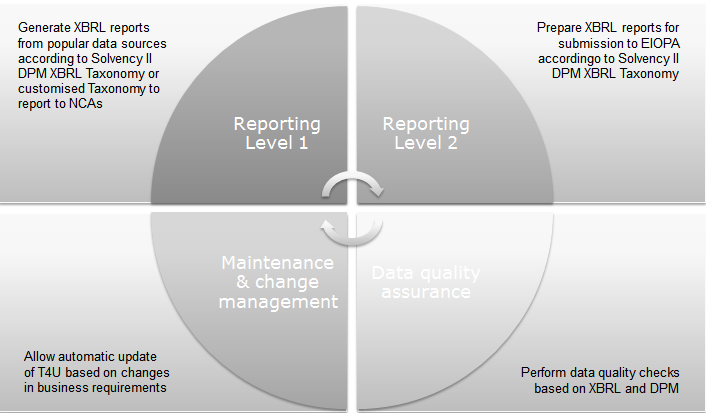
The aim of the tool is to support the undertakings with:
Expected Benefits
- Better reporting by undertakings, in particular smaller ones;
- Economies of scale by developing and sharing software amongst EIOPA’s Members;
- Better control of the reporting chain;
- Reuse in projects like EIOPA’s central repository and the taxonomy project
Out of scope:
- First level support: EIOPA will not provide first level support for the T4U. The tool will be provided on as is basis.
- Submission management: The first level submission procedure will continue to follow the process established by the NCAs.
- Translations of labels: the tool will facilitate the use of translations and will include taxonomy translations if they exist, but is not part of the project to provide actual translations;
- Extension of reporting requirements: however, the tool will provide information on its extension capabilities. Some NCAs might provide and maintain extensions;
- Data consolidation: the undertakings have to obtain the required data from their internal systems. The tool will not provide data consolidation or calculation capabilities. It will only convert provided figures to the XBRL format and provide the defined business validations.
Applications
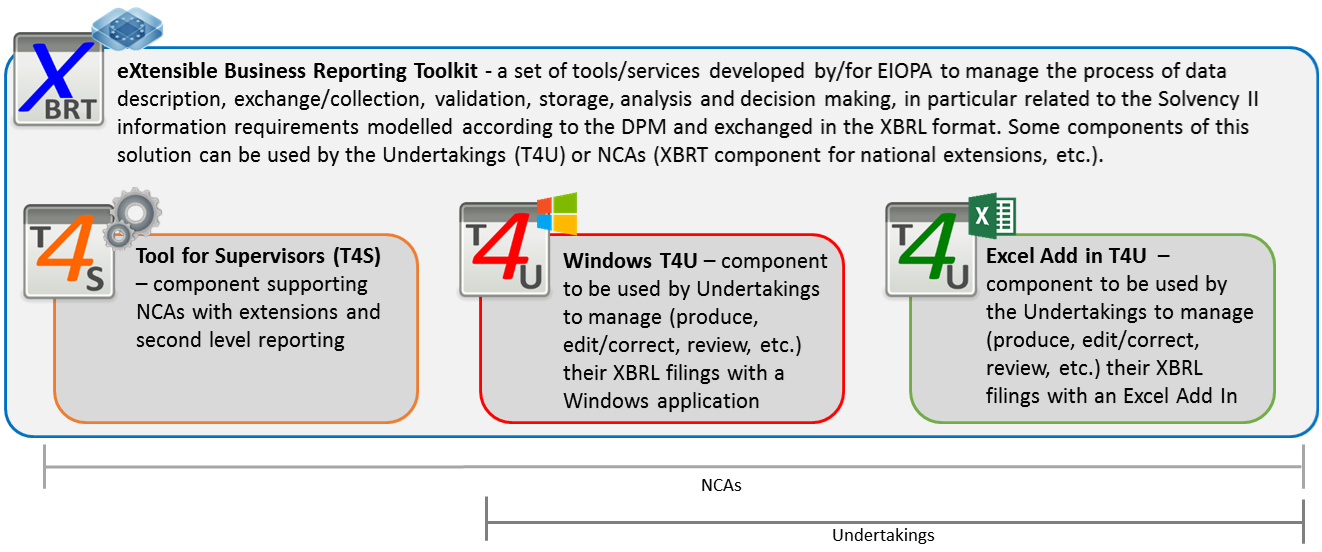
Windows T4U work stream
-
Status note: The first beta is available. Please note that it is not including business validations. Please note that first version that will allow to create 2014

|
|
The Windows T4U application utilizes forms for data entry and storage in a centralized database. It also reuses some other components of XBRT:
- database for data managing, easy deployment and fast validation performance (SQLite); this database uses the same model as the EBA's DPM database and has been upgraded to manage also the storage of data.
- interaction with XBRL validators, currently with the Arelle Opensource XBRL validator; this needs to be installed on the same computer as the Windows T4U, or alternatively the URL of the Arelle Web Server has to be specified within the tool (instructions on how to deploy this feature will be included on this website at a later stage).
Installation
For successful installation the following common components are needed:
- Windows 2000/XP plus .Net Framework 3.5 or above,
- or simply any version of Windows 7 or above.
- Microsoft Excel 2007 or above.
You can install this application by clicking here. If the application does not install correctly please download the
Compressed_T4U_Preparatory_clickonce.zip extract and execute the setup.exe with administrator rights (you need to actually disconnect of Internet). Please read the installation notes section.
Video demonstration
Including general overview of the Windows T4U project. Windows T4U demo. Windows T4U forms generation.
Update on current status by 31/07/2014.
Excel Add-In T4U work stream
-
Status note: This development has not started and still to be confirmed, second priority after Windows T4U

|
|
Tool for Supervisors work stream
-
Status note: Development of this stream to be confirmed,second priority after Windows T4U
|
|
|
Technical Architecture Overview
Video Introduction
High Level View
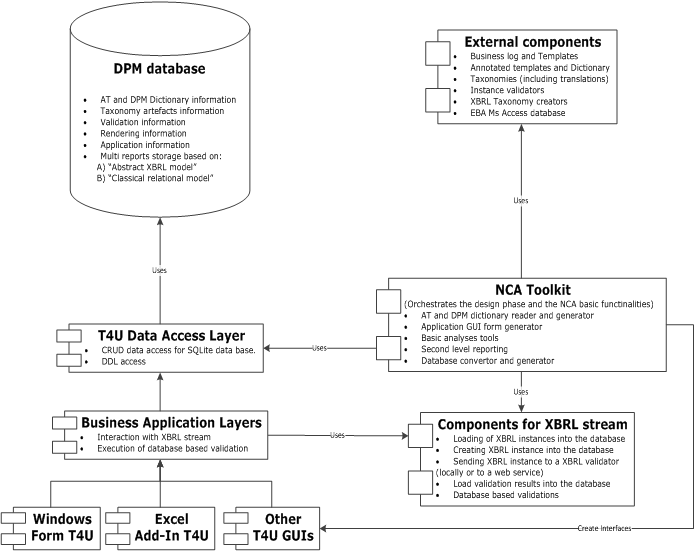
This section and the above diagram aim to provide a simplified view of the solution for explanatory purposes in order to understand the architecture and the philosophy applied within the project. The next two sections will provide a more detailed view of every component and process.
The idea of the project is to create a solution to help insurance undertakings with a tool to convert and validate Solvency II information from Excel files (or other data sources) to XBRL instances and the other way around. At same time the NCAs and EIOPA will have the need of being able to handle this information once it has been received.
Database centric approach (DPM database)
Taking into account the requirements it is expected that having a database-centric project can help to simplify both problems. The database hosts the reporting requirements and the reported data and provides a level of abstraction of the XBRL layer to avoid complex XBRL implementations and facilitate the handling of large XML files.
The core part of the solution is a database whose content is populated from the DPM Dictionary and the Annotated Templates.
The automatic processes
The database can be automatically populated (and updated) from the DPM Dictionary and Annotated Templates. There is therefore an automatic process of updating the solution when information requirement changes are included in the Annotated Templates and Dictionary. In this process a set of validations is checked and the user will receive a validation feedback in case an error is detected.
The database stores all information from the DPM Dictionary and Annotated Templates including definitions of metrics (and their properties), hierarchies of metrics, domains and their members and hierarchies, dimensions, modules, table groups, tables, their axes, axis ordinates (labels and relation to dictionary concepts), etc. These definitions include data type constraints on metrics (where applicable) as well as codes, labels, etc. Also the database stores information on business validations, tools labels, versioning, other taxonomy artefacts, etc.
Generation of interfaces
Graphical user interfaces (Windows Forms, Excel Add-in, etc.) use the metadata from the database to automatically create forms linking the cells on the forms to part of the database representing gathered data (for retrieval, validation and storage). Therefore the graphical representation of tables (XBRL table Linkbase) stored in the database is subsequently used by application GUIs (Windows Forms, Excel Add-In, etc.) to automatically create the input forms (or spreadsheets) sharing a business and data access layer. The input forms, resembling tabular views from the Annotated Templates, allow the EIOPA/NCA users to modify them if needed to fully resemble the original Business Tables, add formatting for colours and fonts, etc. and save for further usage by the filers (undertakings).
Data storage and validation
The database supports the description of metadata and storage of data for closed tables, with any number of rows and columns, and open tables with a (typically) unknown/unlimited number of rows. In terms of storage of undertaking data the database is designed to store more than one report in the same database.
Also it is designed to provide two general structures of data storage, one closer to the XBRL point of view (abstract layer based on facts, dimensions, etc.), and alternatively a second one provides a storage in a more “classical relational” point of view. This classical relational storage is similar to the render view of the tables, or how the table looks like in the annotated templates. This means having in general one table and one column per Annotated Template table and column. This structure may help non XBRL experts to do data migration and has different benefits for the data access layers of the entry tools (Windows and Excel tools).
The XBRL stream: Business rules with XBRL assertions and database based validations
The XBRL stream and in particular the XBRL parser is the part of the solution which is able to produce XBRL instance documents from the database as well as load any valid XBRL instance document to the database. Once data is in the database, it can be retrieved by data entry interfaces and presented to the users. This process will integrate as well XBRL validation, including formulas using third party software (implemented with Arelle).
Validity of the XBRL instance produced by the solution will be assured in multiple ways. Firstly, the database constraints and stored procedures/triggers will not allow or at least identify invalid content as well as perform quality assurance for more complex and demanding rules. Secondly, the XBRL parser produces the XBRL instance according to the tested rules which will assure proper generation. And finally, the solution will use an open source XBRL processor (Arelle) with validation capabilities for XBRL 2.1, Dimensions 1.0, Formula 1.0 and other XBRL and related specifications.
Before the creation of and XBRL instance, data will be tested on input (for example datatype checks in GUIs), in the database (stored procedures/triggers, etc.) and when exporting to XBRL format (tested rules). At each stage there will be pop-up windows or logs with errors. Furthermore, the XBRL instance document can be validated with the plugged-in Arelle.
Design and reporting processes
The following processes/flows describe the desired final outcome:
-
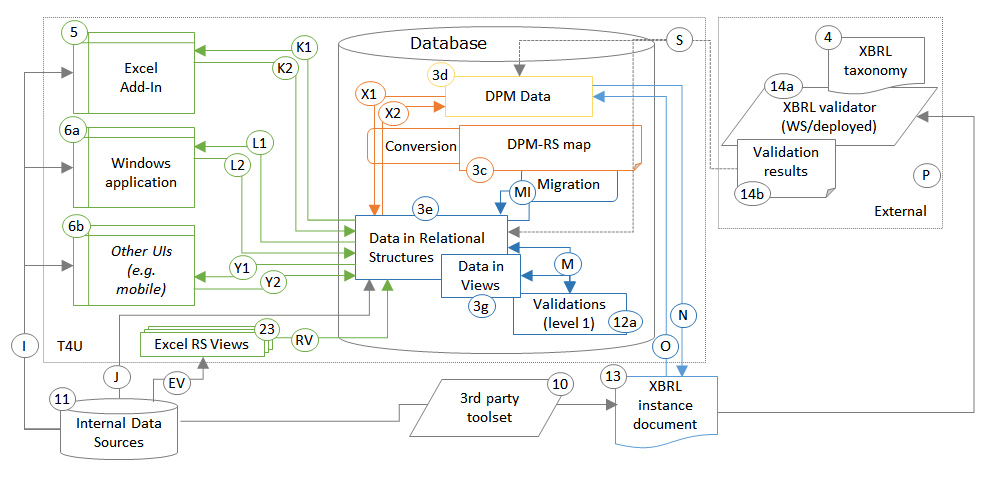
The Design process/flow (setup) presents the components and links required during the development of the solution,
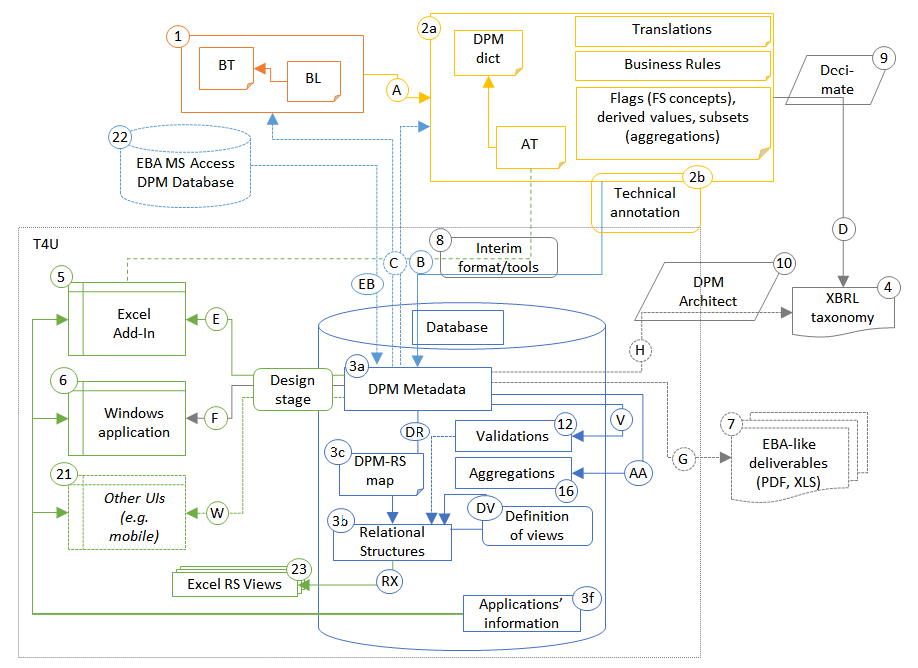

- The primary reporting shows components and links applied in the process of the creation of XBRL reports by undertakings,
-
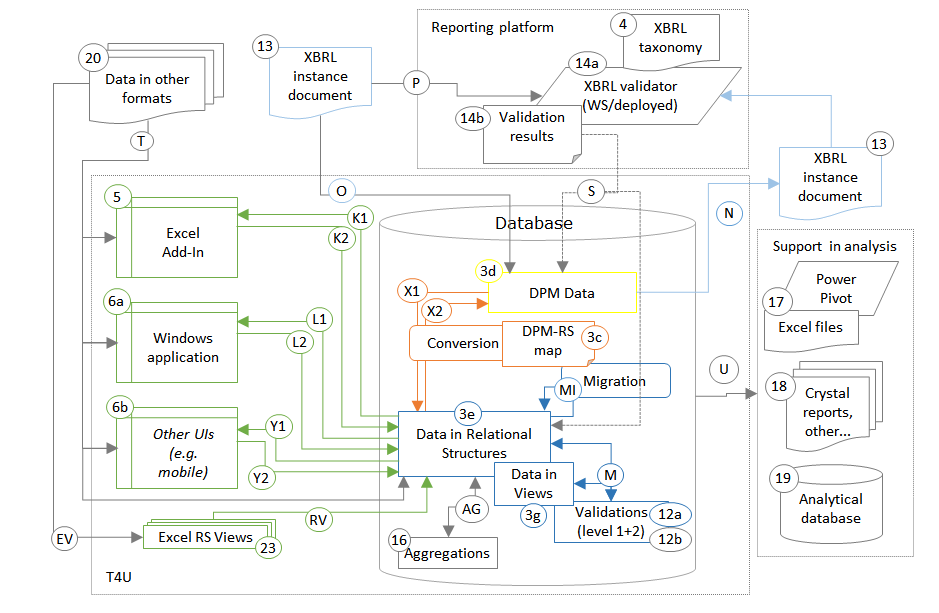
The Secondary reporting shows components and links used in the case of local/national supervisors (NCAs) collecting data from supervised entities and producing XBRL reports that could be sent to EIOPA,
Primary reporting:
Secondary reporting:

Click for a detailed list of components (Boxes) and links (Arrows)
The T4U DPM Database

Introduction
The T4U database consist of the following components:
- information requirements and validations metadata – resembling the DPM dictionary, annotated templates and validation rules metadata,
- placeholder for data storage by reference to DPM properties,
- tables whose structure resembles information requirements and is based on tabular views – these are placeholders for data storage in classic relational manner; this component comes also with information on mapping between DPM metadata/data description and classic relational structures,
- T4U applications information, to be used by the tool for undertaking applications (mainly user interfaces) for localisation purposes (translation of menu options, buttons, messages, etc. to national languages).
Components described above are schematically presented on below figure.
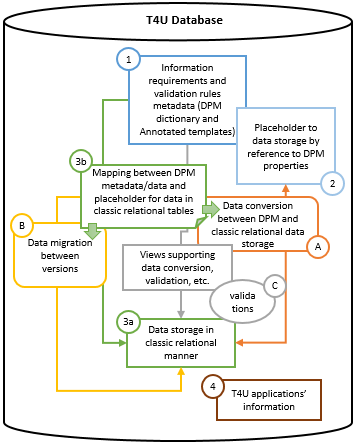
The additional processes occurring in the T4U database include:
- data conversion between DPM and classic relational data storage,
- data migration between versions,
- validations (including and views supporting data validation and aggregations).
Each component and process inside of the T4U database correspond to particular functionality of the solution.
Information requirements and validations metadata (component 1 on Figure 1) is populated in the design/setup stage from the input materials (DPM dictionary and annotated templates, EBA DPM MS Access database). Therefore it reflects all characteristics defined by these sources. Following the normalized DPM model, the structure (entities, their properties and relationships) of this component is relatively stable and able to accommodate any expected future versions. It is also flexible enough to allow for storage of any NCA extension metadata. As explained later, this component is used by the solution in the various stages and process. One of the major tasks is to support navigation over the information requirements and present them in the tabular format as in the source materials.
Definition of information requirements in this component is both, data and from centric. On one hand it defines data cells by identifying its dimensional properties, on the other the cells are gathered in tables with their columns and rows defined in a very normalized manner (represented as ordinates on axis).
This data centric description allowed for definition of placeholders to data storage according to the DPM properties (component 2 on Figure 1) which facilitate interaction with XBRL instance documents files which are constructed in a similar manner. Therefore this component is act to interact with XBRL parser/process for load of XBRL instance document data to the database as well as produce XBRL instance documents from the data in the database in a fast manner.
The problem with data centric approach is complexity of highly normalized model (the manner in which tabular views are resembled is not very intuitive or easy to understand and query by users not familiar with the DPM methodology) and potential performance problems when accessing facts - all facts are stored in a single table with reference to multiple dimensions which hinders prompt rendering or execution of validation rules.
As a result the T4U database contains also placeholders for data storage in classic relational manner (component 3b on Figure 1), i.e. the facts are stored according to their presentation in business templates by reference to row/column position. In consequence, “open” tables in the database look identical to their representation in the information requirements i.e. each column in the business template has its counterpart in the database table for this template. For “closed” templates, every cell becomes a column in the database table (one table for each template) and multiplication of the template (resulting for example from the z-axes properties) are row keys in these database tables.
Video explanation, documentation and examples
A explanatory document, database and instance examples are available within the T4U
Other T4U Resources
XBRL parsers and Arelle integration
Deployment and testing
Useful links
https://eiopa.europa.eu/publications/eu-wide-reporting-formats/index.htmlhttp://www.eurofiling.info/
http://arelle.org/
Support/Contact
Should you have any question contact ToolForUndertakings '@' eiopa.europa.eu and we will help you sort them out.
↑ top